DSIT: GOV.UK Chat
GOV.UK Chat is our AI-powered chatbot that allows users, for the first time, to get quick, personalised answers to their questions based on GOV.UK guidance
1. Summary
1 - Name
GOV.UK Chat
2 - Description
GOV.UK Chat is our AI-powered chatbot that allows users, for the first time, to get quick, personalised answers to their questions based on GOV.UK guidance
3 - Website URL
https://www.gov.uk/government/publications/govuk-chat-privacy-notice/govuk-chat-privacy-notice
4 - Contact email
govuk-chat-beta@digital.cabinet-office.gov.uk
Tier 2 - Owner and Responsibility
1.1 - Organisation or department
GDS
1.2 - Team
Products & Services, AI Team
1.3 - Senior responsible owner
Director of Products and Services
1.4 - Third party involvement
Yes
1.4.1 - Third party
Anthropic
1.4.2 - Companies House Number
Anthropic: 14604577
1.4.3 - Third party role
Anthropic provided general advice on how best GOV.UK used their products by talking through our proposed approaches and offering suggestions. Anthropic provided engineering support to assist the GOV.UK to discuss the best ways to develop using their technology
1.4.4 - Procurement procedure type
Anthropic Joint Innovation Vehicle
1.4.5 - Third party data access terms
No third parties have been granted access to data for the purposes of developing GOV.UK Chat
Tier 2 - Description and Rationale
2.1 - Detailed description
GOV.UK Chat is a Retrieval Augmented Generation-based (RAG) chat system to help GOV.UK users navigate and consume GOV.UK content in an easy to consume manner. GOV.UK Chat is designed to only utilise GOV.UK content for any answer it develops and specifically requests the LLM uses to ignore any of its previous training data. GOV.UK use a LLM (hosted by AWS on our behalf) to process questions made by users about any queries they have regarding our content and issues they may be facing at the time. An example of this is: “How do I apply for a UTR?” which is a specific query about a unique tax record number and something we can answer by processing GOV.UK content. The key aspects of the system are: 1. Our content ‘vectorstore’ database. This is a database of a subset of the GOV.UK content corpus. The content is firstly filtered for document types likely to contain personal data which are then removed. Then, any content deemed acceptable is ‘vectorised’ or transformed into a special numerical format which enables rapid semantic searches to be performed on it. 1. Our logic system is running on GOV.UK infrastructure hosted by AWS. This logic system performs all the necessary steps to orchestrate the question and answer sessions for users. 1. Our Large Language Model is provided by Anthropic and is hosted within a GOV.UK AWS Account using the AWS Bedrock environment. This provides a private instance of that LLM restricting access to any data provided to people with access to that AWS account. 1. The GOV.UK App is the only mechanism available to the general public to access GOV.UK Chat. The App is produced by a team within the Products and Services Directorate and is available on both major platforms (iOS and Android). 1. The GOV.UK Chat Admin system is an application only available to the GOV.UK AI Team members to administer and manage the Chat application. This is used to view overall system performance as well as answer quality questions and to highlight any malicious usage by users. 1. We use the Google BigQuery system to perform more detailed analysis of the question and answer data to ensure we are providing high-quality responses as well as other analyses.
2.2 - Benefits
GOV.UK Chat will reduce barriers to accessing government services by providing 24/7 assistance in natural language. By making information more accessible and understandable, it will help more citizens engage with digital government services, supporting the wider digital transformation agenda and reducing reliance on traditional channels. GOV.UK analysis work and user research from the private beta showed that GOV.UK Chat was faster and easier to use than solely browsing GOV.UK to find an answer, and is comparable to using GOV.UK Search. Users also found that because GOV.UK Chat can pull information from multiple pages at once, it was better starting point to further explore a topic area, than searching or browsing GOV.UK
2.3 - Previous process
There is no comparable legacy process
2.4 - Alternatives considered
GOV.UK Search and navigation are the alternative routes for finding content on GOV.UK. These routes do not allow users to explore content through a conversation, or ask questions about the content, which is unique to GOV.UK Chat
Tier 2 - Deployment Context
3.1 - Integration into broader operational process
Integration of the GOV.UK Chat Tool into the GOV.UK App The GOV.UK app integrates the Chat tool as an additional feature to help users access guidance tailored to their specific circumstances. This complements existing functionality that allows users to browse GOV.UK content by topic or search queries, similar to the web experience.
Unlike traditional browse and search functions, which help users locate individual pieces of guidance, the Chat tool can synthesise information from multiple sources to provide more contextualised and personalised responses based on the user’s question.
Role of the Algorithmic Tool in Operational Processes Purpose and Functionality: The tool provides users with AI-generated guidance based on GOV.UK content. It does not make decisions or take actions on behalf of users. Instead, it supports users in understanding complex topics and navigating relevant government services.
Information Provided: The tool re-articulates existing GOV.UK content into concise, user-friendly responses tailored to the user’s query. Each response includes links to the original source material, allowing users to verify the information and explore further.
Use of Information: Users are encouraged to consult the linked GOV.UK content to validate the guidance and continue their journey. The tool acts as a first step in helping users frame their needs and identify relevant resources, but it does not replace official advice or decision-making processes.
Operational Integration: The tool is embedded within the GOV.UK app as a self-service feature. It supports the broader operational goal of improving access to government guidance by reducing reliance on manual search and enhancing user experience through conversational interaction.
3.2 - Human review
A user of the tool will see which pages on GOV.UK have informed the answer they have received. The user is encouraged to check these pages to continue their journey, and verify the information given in the answer provided by the tool.
3.3 - Frequency and scale of usage
The tool is being tested in a limited fashion, up to a maximum of 2000 users for a 4 week test period. After this, access to the tool will be removed.
3.4 - Required training
When users access GOV.UK Chat for the first time, they will be guided through an onboarding flow that introduces the tool, explains that it is powered by AI and may occasionally produce inaccurate responses. Each answer includes links to relevant GOV.UK content, which users are encouraged to consult for verification. GOV.UK Chat is designed to be intuitive and easy to use, requiring no specialist skills.
3.5 - Appeals and review
No decisions are made or assisted by the tool. The tool provides summaries of GOV.UK guidance only.
Tier 2 - Tool Specification
4.1.1 - System architecture
The key aspects of the system are: 1. The content ‘vectorstore’ database. This is a database of a subset of the GOV.UK content corpus. The content is firstly filtered for document types likely to contain personal data which are then removed. Then, any content deemed acceptable is ‘vectorised’ or transformed into a special numerical format which enables rapid semantic searches to be performed on it. We use a managed instance of AWS OpenSearch for this. 1. The logic system is running on GOV.UK infrastructure hosted by AWS. This logic system performs all the necessary steps to orchestrate the question and answer sessions for users. The GOV.UK Chat team use the GOV.UK standards for coding by using Ruby on Rails for the logic running on the standard GOV.UK kubernetes hosting platform. 1. Our Large Language Model is provided by Anthropic and is hosted within a GOV.UK AWS Account using the AWS Bedrock environment. This provides a private instance of the LLM restricting access to any data provided to people with access to that AWS account. GOV.UK Chat are specifically using Anthropic Claude models all hosted within AWS Bedrock. 1. The GOV.UK App is the only mechanism available to the general public to access GOV.UK Chat. The App is produced by a team within the Products and Services Directorate and is available on both major platforms (iOS and Android). 1. The GOV.UK Chat Admin system is an application only available to the GOV.UK AI Team members to administer and manage the Chat application. This is used to view overall system performance as well as answer quality and to highlight any malicious usage by users. Access to this system is managed by the GOV.UK Signon service and all access is logged for audit purposes. 1. GOV.UK Chat team uses the Google BigQuery system to perform more detailed analysis of the question and answer data to ensure we are providing high-quality responses as well as other analyses.
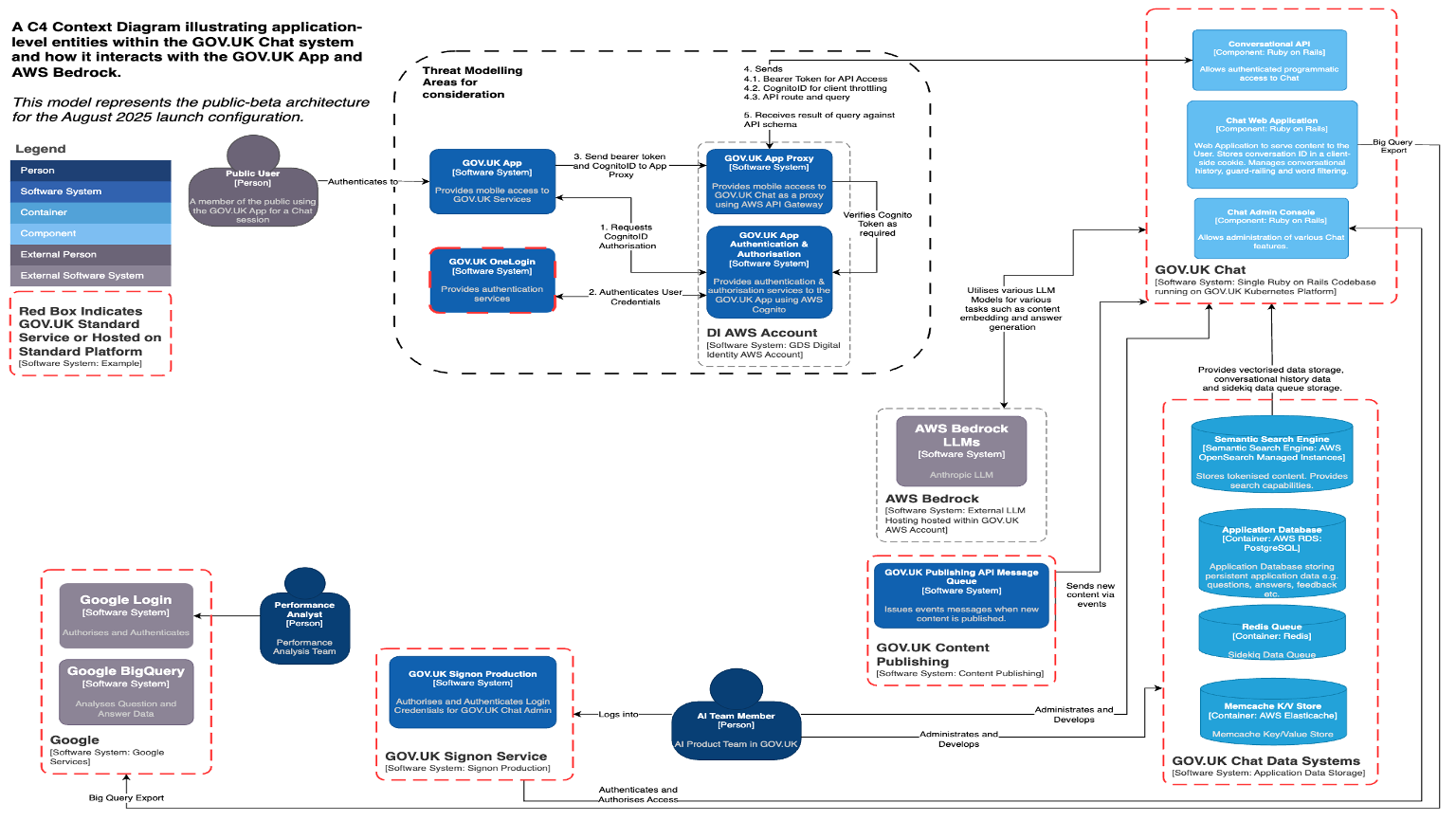{kind=link}
4.1.2 - System-level input
Natural language input by human users via the GOV.UK App
4.1.3 - System-level output
Natural language output generated by the LLM from relevant GOV.UK content and previous question and answer examples.
4.1.4 - Maintenance
GOV.UK do not train this model. It is a foundation model and we constantly monitor for updates or changes that may affect our system performance.
4.1.5 - Models
GOV.UK use Anthropic’s Claude 4 models that are not further distilled or trained in anyway by GOV.UK.
Tier 2 - Model Specification
4.2.1. - Model name
Large Language Model: Claude Sonnet-4 as available on AWS Bedrock, Ireland EU region via cross-regional inference. Model ID: eu.anthropic.claude-sonnet-4-20250514-v1:0
Embedding model: Titan as available on AWS Bedroc, Ireland EU region. Model ID: amazon.titan-embed-text-v2:0
4.2.2 - Model version
LLM Model ID: eu.anthropic.claude-sonnet-4-20250514-v1:0
Embedding model ID: amazon.titan-embed-text-v2:0
4.2.3 - Model task
Within the chatbot, large language models (LLMs) are used to support several distinct sub-tasks, each forming part of the end-to-end user interaction flow. These include:
Query classification and routing: The LLM classifies incoming user queries into predefined categories or intents. This classification determines and generates the appropriate response strategy.
Answer generation via Retrieval-Augmented Generation (RAG): The LLM is used to generate natural language answers based on relevant content retrieved from trusted sources (gov.uk). The retrieved documents provide the context, and the LLM composes a response grounded in that context.
Answer quality and guardrails: The LLM also plays a role in evaluating responses to ensure they meet predefined quality and safety standards.
These sub-tasks enable the chatbot to provide accurate, relevant, and safe information in response to a wide variety of user queries.
4.2.4 - Model input
User questions. Chunks of GOV.UK content.
4.2.5 - Model output
An answer to the user question produced using GOV.UK content, and a list of GOV.UK sources used to generate the answer
4.2.6 - Model architecture
https://www.anthropic.com/news/claude-4
4.2.7 - Model performance
The GOV.UK Chat team applied a hybrid evaluation approach combining automated and manual methods.
Automated evaluation was used to iteratively develop and benchmark system components, leveraging tailored test sets and metrics suited to each task. For classification-based components, the team applied standard information retrieval metrics (e.g., precision, recall) alongside qualitative error analysis. For answer-generation, the GOV.UK Chat team employed LLM-as-a-Judge metrics to quantify answer quality dimensions such as factual precision, factual recall, relevancy, and groundedness.
Beyond automated evaluation, we conduct structured manual evaluations to capture answer accuracy, answer completeness, and interaction quality, producing performance estimates for internal communication and stakeholder alignment. We also perform red teaming, systematically probing the chatbot with adversarial and edge-case inputs to uncover vulnerabilities and safety risks. Together, these methods provide both a realistic view of end-user experience and a risk-aware perspective on system performance.
4.2.8 - Datasets and their purposes
This chatbot uses a third-party large language model (LLM) and does not involve training any models internally. No datasets have been produced or used to train the LLM.
However, the GOV.UK Chat team have developed internal datasets to support evaluation and improvement of the chatbot’s performance. These datasets are used solely for testing and iteration purposes. They typically consist of:
Examples of user questions paired with an “ideal answer”, used to evaluate the quality of the chatbot’s responses.
Classification test cases, such as user questions paired with the correct routing label or category, to assess and improve the chatbot’s ability to route queries accurately.
These datasets are not publicly available at present, but they are used only for evaluation, not for training or fine-tuning any models.
2.4.3. Development Data
4.3.1 - Development data description
The tool uses publicly available content from GOV.UK
4.3.2 - Data modality
Text
4.3.3 - Data quantities
The vector store, which is used in the retrieval step of the chatbot, is estimated to have approximately 100,000 GOV.UK pages, subject to daily changes. In practice, when split into chunks according to the semantic hierarchy of headers, it currently contains roughly 700,000 chunks/documents and occupies 36.9 GB.
This chunking approach allows the retrieval step to operate at a more granular level, improving relevance when matching user queries to the underlying content.
4.3.4 - Sensitive attributes
The GOV.UK content dataset, comprising over 700,000 pages, undergoes a filtration process to identify and exclude any personal data before being sent to the vector database. Estimated at being about 100,000 pages as this changes daily. This filtration process is designed to ensure that any personal data is removed from the dataset prior to transmission by way of filtering entire documents likely to contain any personal data based on the documents’ metadata. A detailed paper on the filtration methodology is available, along with an analysis of its effectiveness.
The user’s query is checked for any common formats of personal data at first input. The Chat system checks using regular expressions the query for common data types including phone numbers, email addresses and credit card numbers and on detecting any single item, the query is rejected and the user informed. Explainer: regular expressions are a programmatic way of identifying patterns of data. For example, if the system detects something@somethingelse.something i.e. some text with an @ symbol in the middle with no spaces, we can safely conclude it’s an email address. We do this for several common forms of personal data. If the system detects a string of 16 numerical characters without any letters in between them, we can safely conclude that it is a credit or debit card number.
4.3.5 - Data completeness and representativeness
N/A
4.3.6 - Data cleaning
In order to remove any (primarily) personal data and (secondly) to remove content deemed unsuitable for use with a chatbot-type system, the GOV.UK content dataset, comprising over 700,000 pages, undergoes a filtration process to identify and exclude any personal data before being sent to the vector database. Estimated at being about 100,000 pages as this changes daily. This filtration process is designed to ensure that any personal data is removed from the dataset prior to transmission by way of filtering entire documents likely to contain any personal data based on the documents’ metadata. A detailed paper on the filtration methodology is available, along with an analysis of its effectiveness.
4.3.7 - Data collection
We use content published on GOV.UK to provide an authoritative and trustworthy source of content for GOV.UK Chat to answer user queries
4.3.8 - Data access and storage
The development data is public GOV.UK content pages
4.3.9 - Data sharing agreements
GDS are the data controller for GOV.UK content
Tier 2 - Operational Data Specification
4.4.1 - Data sources
The tool receives a user question via a TLS HTTP request. Should we deem the users questions valid and not containing PII, the question will be written to persistent storage. This persistent storage is an AWS RDS PostgreSQL Database. The data is encrypted, and unreadable, while in transfer and while it is stored.
The next step in the process is the process of answering a question. This involves the tool reading the question from the aforementioned database. This question is then used in requests to invoke two distinct models on AWS Bedrock: Claude Sonnet 4 and AWS Titan Embedding 2. This communication happens securely over TLS. The result of this process is the production of an answer that is also persisted to the AWS RDS Postgres Database.
In answering a question the tool makes use of a search index of GOV.UK content, which is stored in Amazon OpenSearch. The search index is queried for content semantically similar to the users question. The search index is populated by GOV.UK content via a message queue (AmazonMQ) provided by the GOV.UK application Publishing API, which sends a JSON representation of a piece of content each time one is published or updated.
4.4.2 - Sensitive attributes
The Chat system checks all incoming questions using regular expressions for common data types including phone numbers, email addresses and credit card numbers and on detecting any single item, the query is rejected and the user informed.
Regular expressions are a programmatic way of identifying patterns of data. For example, if the system detects something@somethingelse.something i.e. some text with an @ symbol in the middle with no spaces, we can safely conclude it’s an email address. We do this for several common forms of personal data. For example, if the system detects a string of 16 numerical characters without any letters in between them, we can safely conclude that it is a credit or debit card number.
If something does get past the initial checks, the data will be processed by the AI Model in later steps. These steps include an assessment of the question and whether or not we are likely to be able to answer it all the way to answer generation. However, our response guardrails will very likely detect any personal data in an answer it has produced and refuse to provide that answer to the user.
Explainer: Response Guardrails The response from the LLM is reprocessed to check that its language, tone and other aspects meet our quality expectations. The response is passed through another LLM filtering for any advice that might be given, language, tone and quality which is outside of tolerance. The results are only passed to the user once passed by the guardrails.
4.4.3 - Data processing methods
No additional pre-processing
4.4.4 - Data access and storage
User questions, their resulting answers and the details of the individual LLM responses are stored in the system for 12 months. It is stored in AWS RDS database which is encrypted at rest.
This data can be accessed by GOV.UK AI team members who are responsible for the monitoring and analysing of the chat applications responses. These users need to be granted access via permissions.
The GOV.UK AI team take responsibility for the management of this data.
4.4.5 - Data sharing agreements
There are no data sharing agreements in place
Tier 2 - Risks, Mitigations and Impact Assessments
5.1 - Impact assessments
DPIA - completed September 2025 Secure by Design framework - completed September 2025 IT Health Check - completed September 2025
5.2 - Risks and mitigations
Risk of Jailbreaking: Jailbreaking is when a user elicits an output from GOV.UK Chat that is outside its intended use. With all chat based AI, jailbreaking is a possibility. Jailbreaking generally occurs after intentional action from a user. Mitigation: The GOV.UK Chat team done jailbreaking assessments with the AI Security Institute (AISI) and as part of our IT Health Check (ITHC), to test aspects of the system which detect and prevent jailbreaking attacks. While both highlighted the overall resilience of the Chat, they also point out that it’s not possible to guarantee no jailbreaking attempts will be successful. We have blogged publicly about jailbreaking and our approach to this risk.
Risk of Inaccurate Responses: With any AI tool there is a risk of inaccurate responses. For GOV.UK Chat, this would mean that Chat has provided inaccurate information in response to a user query. Mitigation: GOV.UK Chat have tested across a range of topic areas using automated and manual evaluation processes, assessing accuracy of responses, how grounded they are on GOV.UK content, and how complete the response is. GOV.UK Chat team have iterated to improve for accuracy, and have seen continual improvement with the current version of Chat beating industry standards. The GOV.UK Chat team have undertaken actions to ensure all users of Chat are aware that the answers may be inaccurate, and that they should check their answers. Links to pages used to generate an answer are always provided to users, alongside a reminder to check their answers.