Community and Engagement Survey October to December 2025: Technical Report
Updated 28 May 2026
Applies to England

© Crown copyright 2026
This publication is licensed under the terms of the Open Government Licence v3.0 except where otherwise stated. To view this licence, visit nationalarchives.gov.uk/doc/open-government-licence/version/3 or write to the Information Policy Team, The National Archives, Kew, London TW9 4DU, or email: psi@nationalarchives.gov.uk.
Where we have identified any third party copyright information you will need to obtain permission from the copyright holders concerned.
This publication is available at https://www.gov.uk/government/statistics/community-and-engagement-survey-october-to-december-2025/community-and-engagement-survey-october-to-december-2025-technical-report
1. Introduction
1.1 Background to the survey
In 2025, the Department for Culture, Media and Sport (DCMS) launched the Community and Engagement Survey (CES), with the support of the Ministry for Housing, Communities and Local Government (MHCLG). CES brings together DCMS’ Participation Survey and Community Life Survey, and runs them jointly. This is in response to a public consultation about DCMS’ social surveys which was run in 2024. Independent research agency Verian, who previously worked with DCMS on both the Participation and Community Life Surveys, was commissioned to design and deliver the CES.
This technical note relates to the 2025/26 Community and Engagement Survey Quarter 1 fieldwork, conducted between 4th October and 31st December 2025. Full details of the survey will be covered in the annual technical report, due to be published in summer 2026.
The scope of the survey is to deliver a nationally representative sample of adults (aged 16 years and over) and to assess adult participation in DCMS’ sectors and community life across England. The data collection model for the Community and Engagement Survey is based on ABOS (Address-Based Online Surveying), a type of ‘push-to-web’ survey method. Respondents take part either online or by completing a paper questionnaire and are allocated to either the Community or Engagement pathway through the survey.
For 2025-26 DCMS have partnered with MHCLG to boost the respondent sample size to 175,000 for the Community pathway. For the Engagement pathway, the target respondent sample size of 33,000 is derived from a sample of 16,500 in the last two quarters of the standalone Participation Survey (April - September 2025) and 16,500 in the first two quarters of CES (October 2025 - March 2026). Further information about the CES is available on the DCMS Community and Engagement Survey webpage.
Figure 1.1: The Community and Engagement Survey flow

1.2 Survey objectives
Across both pathways, the Community and Engagement Survey provides the following:
-
Robust, nationally representative data on behaviours and attitudes within communities that can be used to inform and direct policy and research in these areas.
-
Evidence for policymakers in government, public bodies, voluntary, community and social enterprise (VCSE) sector organisations and other external stakeholders.
-
Measures of loneliness in England.
-
Monitoring and informing government policy and programmes in DCMS and other government departments (OGDs) on adult engagement with the DCMS sectors.
-
Assessing the variation in engagement with cultural activities across DCMS sectors in England, and the differences in socio-demographics such as location, age and education.
1.3 Survey design
The basic ABOS design is simple: a stratified random sample of addresses is drawn from the Royal Mail’s postcode address file and an invitation letter is sent to each one, containing username(s) and password(s) plus the URL of the survey website (a QR code is also provided for those who prefer to access via this method).
Sampled individuals can log on using this information and complete the survey as they might any other web survey. Once the questionnaire is complete, the specific username and password cannot be used again, ensuring data confidentiality from others with access to this information.
It is usual for at least one reminder to be sent to each sampled address, and it is also usual for an alternative mode (usually a paper questionnaire) to be offered to those who need it or would prefer it. It is typical for this alternative mode to be available only on request at first. However, after non-response to one or more web survey reminders, this alternative mode may be given more prominence.
Paper questionnaires ensure coverage of the offline population and are especially effective with sub-populations that respond to online surveys at lower-than-average levels. However, paper questionnaires have measurement limitations that constrain the design of the online questionnaire and also add considerably to overall cost. For the Community and Engagement Survey, paper questionnaires are used in a limited and targeted way, to optimise rather than maximise response.
2. Sampling
2.1 Sample design
2.1.1 Sample design: addresses
The address sample design is intrinsically linked to the data collection design (see ‘Details of the data collection model’ below) and was designed to yield a respondent sample that is representative with respect to neighbourhood deprivation level and age group within each of the 296 local authorities, 36 ITL2 regions [footnote 1] and 9 ITL1 regions in England. This approach limits the role of weights in the production of unbiased survey estimates, narrowing confidence intervals compared with other designs.
The design sought a minimum two-quarter respondent sample size of 500 allocated to the Community module per local authority[footnote 2] and 450 allocated to the Engagement module per ITL2 region. Although there were no specific targets per quarter, the sample selection process was designed to ensure that the respondent sample size per local authority and per ITL2 region was approximately the same per quarter.
As a first step, a stratified master sample of 1,706,290 addresses in England was drawn from the Postcode Address File (PAF) ‘residential & small user’ subframe. Of these, 1,595,151 were eligible to issue (eligible = not issued for either the Community Life or Participation Surveys since 2022-23 (unless in the Isles of Scilly or City of London)). Before sampling, the PAF was disproportionately stratified by lower tier local authority (296 strata) and, within local authority, sorted by (i) neighbourhood deprivation level (five groups, each of a similar scale at the national level), (ii) medium layer super output area, (iii) lower layer super output area, (iv) census output area, (v) postcode, and finally (vi) first line of address. This ensured that the master sample of addresses was geodemographically representative within each stratum.
This master sample of addresses was then augmented by data supplier CACI. For each address in the master sample, CACI added the expected number of resident adults aged 16 and over in each ten-year age band. Although this auxiliary data will have been imperfect, investigations by Verian have shown that it is highly effective at identifying households that include older people. Once this data was attached, the master sample was additionally stratified by expected household age structure based on the CACI data:
(i) any aged 65 or older (28% of the total)
(ii) other addresses (72% of the total)
The conditional sampling probability in each stratum was varied to compensate for (expected) residual variation in response rate that could not be ‘designed out’, given the constraints of budget and timescale. The underlying assumptions for this procedure were derived from empirical evidence obtained from the 2024/25 Community Life Survey.
Verian drew a stratified random sample of 853,208 addresses from the master sample of 1,595,151 and systematically allocated them with equal probability to 24 equal-sized ‘replicates’, each with the same profile and scale (35,550-35,551 addresses). The expectation was that only the first 16 replicates would be issued (that is, 568,808 addresses), with the remaining 8 kept back in reserve.
There are four issue points across the six-month 2025/26 survey period: two per quarter, so the expectation was that the next four available replicates in each stratum (local authority) would be activated at each issue point (so, eight per quarter; 16 in the whole survey period). The intention was to carry out a stratum level review towards the end of each quarter to inform the selection of replicates for the following quarter.
For quarter 1, the number of replicates issued per local authority ranged from 6 to 10 with a median of 9 (compared to the expected 8). In total, 322,144 addresses were issued for quarter 1.
Table 1 shows the quarter 1 (issued) sample structure with respect to the major ‘design’ strata: neighbourhood deprivation level and expected household age structure.
Table 1: Initial address issue by area deprivation quintile group and expected household age structure
| Expected household age structure | Most deprived | 2nd | 3rd | 4th | Least deprived |
|---|---|---|---|---|---|
| Any >=65 | 13,520 | 15,572 | 18,092 | 18,509 | 17,578 |
| Other | 57,906 | 54,551 | 48,409 | 41,444 | 36,563 |
2.1.2 Sample design: Individuals within sampled addresses
All resident adults aged 16 and over were invited to complete the survey. In this way, the Community and Engagement Survey avoided the complexity and risk of selection error associated with remote random sampling within households.
However, for practical reasons, the number of logins provided in the invitation letter was limited. The number of logins was varied between two and four, with this total adjusted in reminder letters to reflect household data provided by prior respondent(s). Addresses that CACI data predicted contained only one adult were allocated two logins; addresses predicted to contain two adults aged 16 and over were allocated three logins; and other addresses were allocated four logins. The mean number of logins per address was 2.77. Paper questionnaires were available to those who are offline, not confident online, or unwilling to complete the survey this way.
Every respondent had a fixed probability of being allocated to either the Community or Engagement module. This probability varied between local authorities but not within local authorities. Web respondents were allocated to one of the two modules at the start of the questionnaire using a script-based randomisation tool. Consequently, module allocation could vary between respondents in the same household. In contrast, paper respondents in the same household were allocated to the same module (i.e. the module was allocated at address level rather than at individual level but the same kind of randomisation tool was used for the allocation).
2.2 Details of the data collection model
For every sampled address, one of four data collection strategies was selected: ‘WW’, ‘WP’, ‘WWW’ or ‘WWP’. This code summarises the data collection design, showing the number of mailings and type of each mailing: push-to-web (W) or mailing with paper questionnaires (P). For example, ‘WWP’ means two push-to-web mailings and a third mailing with paper questionnaires included alongside the web survey login information. In general, there was a two-week gap between mailings.
The selection of data collection strategy was based on (i) an address-level estimate of how the response level would vary under each of the four designs, (ii) whether the address had been coded by CACI as containing someone aged 65+, (iii) a constant that was broadly equivalent to the overall target number of responses per issued address, and (iv) a random number between 0 and 1.
A randomised controlled trial (‘RCT’) was built into the quarter 1 design to allow evaluation of the impact of proactive provision of paper questionnaires (‘P’ mailings) versus reactive provision and of a two-reminder design versus a single reminder design. The random number between 0 and 1 governed the allocation of addresses to trial cell. Every address had a nonzero probability of allocation to each of the four data collection strategies, but the probability of being allocated to a ‘P’ data collection strategy (‘WP’ or ‘WWP’) was much higher if the address had been coded by CACI as containing someone aged 65+ (70% compared to 10% for other addresses).
2.3 Sample sizes
In quarter 1, selected addresses were allocated to two sample issue points for mailing purposes. This allowed for a review of the response from issue point 1 before the sample for issue point 2 was finalised. The sample size for issue point 1 was 142,202 addresses and for issue point 2 it was 179,942 addresses, reflecting a lower-than-expected response from the first sample issue.
Table 2 shows the number of issued addresses allocated to each data collection strategy in quarter 1 as a whole, crossed by household age stratum
Table 2: Data collection design by household age stratum.
| Expected household age structure | WW | WP | WWW | WWP |
|---|---|---|---|---|
| Any >=65 | 18,325 | 45,887 | 12,193 | 6,866 |
| Other | 134,015 | 15,482 | 82,204 | 7,172 |
3. Questionnaire
3.1 Questionnaire development
The survey is split into two pathways, Community and Engagement. In the online questionnaire, allocation is controlled via the survey script; on paper, two separate questionnaires have been developed, with households pre-allocated to one or the other.
Both pathways of the online questionnaire were designed to take an average of 30 minutes to complete. A modular design was used with around two-thirds of each pathway of the questionnaire made up of a core set of questions asked of the full sample for that pathway. The remaining questions were divided into distinct modules, randomly allocated to a subset of the sample. For the Community pathway, there were three subset modules, whilst for the Engagement pathway there were two.
The postal version of the questionnaire included the same set of core questions asked online, but the modular questions were omitted to avoid overly burdening respondents who complete the survey on paper, and to encourage response. Copies of the online and paper questionnaires are available online.
3.2 Questionnaire changes
Substantial work was undertaken to merge the legacy surveys and introduce new questions. Full details of the questionnaire development and changes can be found in the Pilot report, published in March 2026.
3.3 Cognitive testing
Cognitive testing was undertaken in August and September 2025 to test new questions to be included in quarter 1 of the Community and Engagement Survey. A summary of the method and key findings can be found in section 2.2 of the Pilot Report, and here you will find a full report of the cognitive testing.
4. Fieldwork
4.1 Contact procedures
All selected addresses were sent an initial invitation letter containing the following information:
-
A brief description of the survey
-
The URL of survey website (used to access the online script)
-
A QR code that can be scanned to access the online survey
-
Log-in details for the expected number of household members
-
An explanation that participants will receive a £10 shopping voucher
-
Information about how to contact Verian in case of any queries
The reverse of the letter featured responses to a series of Frequently Asked Questions.
All partially or non-responding households were sent one reminder letter at the end of the second week of fieldwork. A further targeted second reminder letter was sent to households for which, based on Verian’s ABOS field data from previous studies, this was deemed likely to have the most significant impact (mainly deprived areas and addresses with a younger household structure). The information contained in the reminder letters was similar to the invitation letters, with slightly modified messaging to reflect each reminder stage.
As well as the online survey, respondents were given the option to complete a paper questionnaire, which consisted of an abridged version of the online survey. Each letter informed respondents that they could request a paper questionnaire by contacting Verian using the email address or freephone telephone number provided, and a cut-off date for paper questionnaire requests was also included on the letters.
In addition, some addresses received up to two paper questionnaires in either the first or second reminder letters. This targeted approach was developed based on historical data Verian has collected through other studies, which suggests that proactive provision of paper questionnaires to all addresses can actually displace online responses in some strata. Paper questionnaires were pro-actively provided to (i) sampled addresses in the most deprived quintile group, and (ii) sampled addresses where it was expected that every resident would be aged 65 or older (based on CACI data).
4.2 Fieldwork timings
The following schedule was used for Quarter 1 of 2025/26. The closing date for the return of paper surveys was set in early January to allow for any delays in returning them caused by the postal service over the December holiday period:
Table 3: Quarter 1 fieldwork timings by batch
| Quarter 1 | Start date | Close date - online survey | Close date - paper survey |
|---|---|---|---|
| Batch 1 | 15th October 2025 | 31st December 2025 | 12th January 2026 |
| Batch 2 | 19th November 2025 | 31st December 2025 | 12th January 2026 |
4.3 Fieldwork performance
In total, 85,326 respondents completed the survey during quarter 1 – Split by the Community pathway 77,835 (Web – 68,931 & Paper – 8,904) and Engagement pathway 7,491 (Web – 6,594 & Paper – 897). Following data quality checks (see Chapter 5 for details), 3,930 respondents were removed from the Community pathway 3,470 (Web – 3,072 & Paper – 398) and 460 (Web – 393 & Paper – 67) from the Engagement pathway, leaving 81,396 respondents in the final dataset.
This constitutes a 0.25 conversion rate (responses/sampled addresses), a 18.69% household-level response rate, and an individual-level response rate of 14.53% [footnote 3].
For the online survey, completion times for the Community and Engagement Survey was an overall median of 33:12 and a mean of 35:57, which separated out as a median of 33:52 minutes and mean of 36:37 minutes for the Community pathway and a median of 26:43 minutes and a mean of 28:47 minutes for the Engagement pathway. Each respondent will have only completed one of the pathways. [footnote 4].
4.4 Incentive system
As a thank you for taking part, all respondents that completed the Community and Engagement Survey received an incentive voucher worth £10.
Online incentives
Participants completing the survey online were provided with details of how to claim their voucher at the end of the survey and were directed to the voucher website, where they could select from a range of different vouchers, including electronic shopping vouchers sent via email, credit to visit heritage sites, or a charitable donation.
Paper incentives
Respondents who returned the paper questionnaire were also provided with a £10 shopping voucher. This voucher was sent in the post and could be used at a variety of high street stores.
5. Data processing
5.1 Data management
Due to the different structures of the online and paper questionnaires, data management was handled separately for each mode. Online questionnaire data was collected via the web script and, as such, was much more easily accessible. By contrast, paper questionnaires were scanned and converted into an accessible format.
For the final outputs, both sets of interview data were converted into IBM SPSS Statistics, with the online questionnaire structure as a base. The paper questionnaire data was converted to the same structure as the online data so that data from both sources could be combined into a single SPSS file.
5.2 Quality checking and assurance processes
Initial checks were carried out to ensure that paper questionnaire data had been correctly scanned and converted to the online questionnaire data structure. For questions common to both questionnaires, the SPSS output was compared to check for any notable differences in distribution and data setup.
Once any structural issues had been corrected, further quality checks were carried out to identify and remove any invalid interviews. The specific checks were as follows:
-
Selecting complete interviews: Any test serials in the dataset (used by researchers prior to survey launch) were removed. Cases were also removed if the respondent reached but did not answer the quality declaration statement (online: QFraud; community paper: Q106; engagement paper Q89).
-
Duplicate serials check: If any individual serial had been returned in the data multiple times, responses were examined to determine whether this was due to the same person completing multiple times or due to a processing error. If they were found to be valid interviews, a new unique serial number was created, and the data was included in the data file. If the interview was deemed to be a ‘true’ duplicate, the more complete or earlier interview was retained.
-
Duplicate emails check: If multiple interviews used the same contact email address, responses were examined to determine if they were the same person or multiple people using the same email. If the interviews were found to be from the same person, only the most recent interview was retained. In these cases, online completes were prioritised over paper completes due to the higher data quality.
-
Interview quality checks: A set of checks on the data were undertaken to check that the questionnaire was completed in good faith and to a reasonable quality. Several parameters were used:
a. Interview length (online check only)
b. Number of people in household reported in interview(s) vs number of total interviews from household.
c. Whether key questions have valid answers.
d. Whether respondents have habitually selected the same response to all items in a grid question (commonly known as ‘flatlining’) where selecting the same responses would not make sense.
e. How many multi-response questions were answered with only one option ticked.
Following the removal of invalid cases, 81,396 valid cases were left in the final dataset.
5.3 Data checks and edits
Upon completion of the general quality checks described above, more detailed data checks were carried out to ensure that the right questions had been answered according to questionnaire routing. This is generally all correct for all online completes, as routing is programmed into the scripting software, but for paper completes, data edits were required.
There were two main types of data edits, both affecting the paper questionnaire data:
-
Single-response question edits: If a paper questionnaire respondent had mistakenly answered a question that they weren’t supposed to, their response in the data was changed to “-1: Item not applicable”. If a paper questionnaire respondent had neglected to answer a question that they should have, they were assigned a response in the data of “-4: Not answered but should have (paper)”. If a paper questionnaire respondent had ticked more than one box for a single response question they were assigned a response in the data of “-5: Multi-selected for single response (paper)”.
-
Multiple response question edits: If a paper questionnaire respondent had mistakenly answered a question that they weren’t supposed to, their response was set to “-1: Item not applicable”. If a paper questionnaire respondent had neglected to answer a question that they should have, they were assigned a response in the data of “-4[footnote 5]: Not answered but should have (paper)”. Where the respondent had selected both valid answers and an exclusive code such as “None of these”, any valid codes were retained and the exclusive code response was set to “0”.
Other, more specific data edits were also made, as described below:
- Additional edits to library questions: The question CLIBRARY1Part was formatted differently in the online script and paper questionnaire. In the online script it was set up as one multiple-response question, while in the paper questionnaire it consisted of two separate questions (Q17 and Q22). During data checking, it was found that many paper questionnaire respondents followed the instructions to move on from Q17 and Q22 without ticking the “No” response. To account for this, the following data edits were made:
a. If CFRELIB12 and CPARLI12B were not answered and CNLIWHYA was answered, set CLIBRARY1Part_001 was set to 0 if it was left blank.
b. If CFRELIDIG and CDIGLI12 were not answered and CNLIWHYAD was answered, CLIBRARY1Part_002 was set to 0 if it was left blank.
c. CLIBRARY1Part_003 and CLIBRARY1Part_004 were set to 0 for all paper questionnaire respondents.
- Additional edits to grid questions: Due to the way the paper questionnaire was set up, additional edits were needed for the following linked grid questions: CARTS1/CARTS1A, CARTS2/CARTS2A, CARTS3/CARTS3A, CARTS4/CARTS4A
Figure 1 shows an example of a section in the paper questionnaire asking about attendance at arts events.
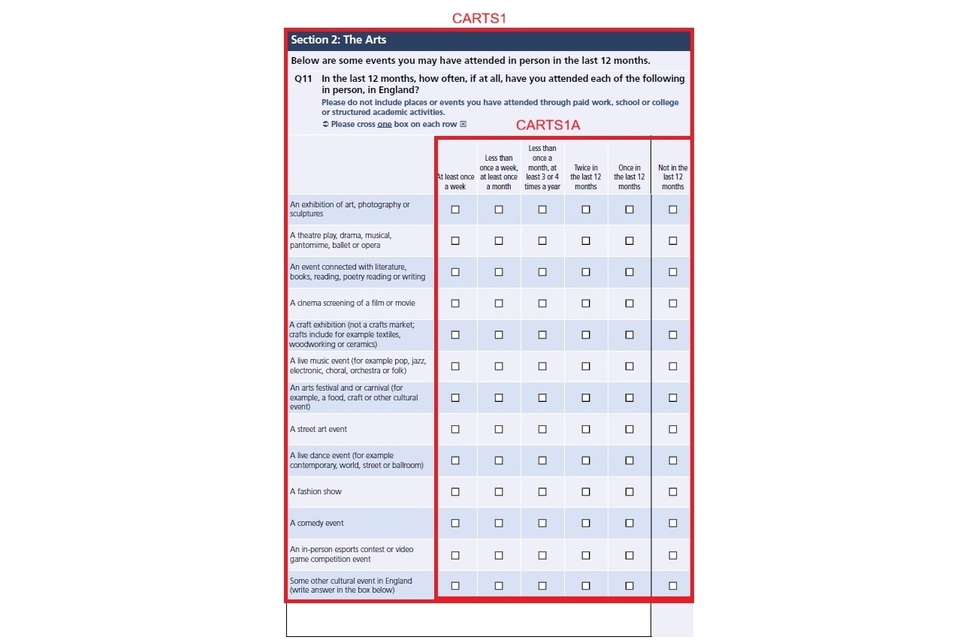
Figure 1: Example of the CARTS1 and CARTS1A section in the paper questionnaire
Marking the option “Not in the last 12 months” on the paper questionnaire was equivalent to the code “0: Have not done this” at CARTS1 in the online script. As such, leaving this option blank in the questionnaire would result in CARTS1 being given a default value of “1” in the final dataset. In cases where a paper questionnaire respondent had neglected to select any of the options in a given row, CARTS1 was recoded from “1” to “0”.
If the paper questionnaire respondent did not tick any of the boxes on the page, they were recoded to “-4: Not answered but should have (paper)”.
5.4 Coding
Post-interview coding was undertaken by members of the Verian coding department. The coding department coded verbatim responses, recorded for ‘other specify’ questions.
For example, if a respondent selected “Other” at CARTS1 and wrote text that said they went to some type of live music event, in the data they would be back-coded as having attended a “a live music event” at CARTS1_006.
Where ‘other specify’ responses could not be back coded to an existing code and where the number of mentions of a particular response was given by at least 2% of those answering the question, new codes were opened to reflect these responses where appropriate – and the relevant responses were coded to these new codes accordingly.
5.5 Data outputs
Once the checks were complete a final SPSS data file was created that only contained valid interviews and edited data.
From this dataset, a set of data tables were produced using R. Due to the changes to the questionnaire structure the tables have also been updated accordingly.
5.6 Weighting
A three-step weighting process was used to compensate for differences in both sampling probability and response probability. This was carried out separately for respondents allocated to the Community module and respondents allocated to the Engagement module but the process was identical.
-
A design weight was created equal to one divided by the product of the address sampling probability and the selected module allocation probability.
-
The expected number of responses per sampled address was modelled as a function of data available at the neighbourhood and address levels at the time of sampling as well as household size data provided by the respondent. The step two weight was equal to the number of adults aged 16 and over in the household divided by the predicted number of responses.
-
The product of the first two steps was used as the input for the final step to calibrate the sample. The responding sample was calibrated to the July to September 2025 Labour Force Survey (LFS) with respect to (i) sex by age, (ii) educational level by age, (iii) ethnic group, (iv) housing tenure, (v) ITL2 region, (vi) employment status by age, (vii) household size, (viii) presence of children in the household, and (ix) internet use by age.
An equivalent weight was also produced for the (majority) subset of respondents who completed the survey by web. This weight was needed because a few items were included in the web questionnaire but not the paper questionnaire.
It should be noted that the weighting only corrects for observed bias (for the set of variables included in the weighting matrix) and there is a risk of unobserved bias. Furthermore, the raking algorithm used for the weighting only ensures that the sample margins match the population margins. There is no guarantee that the weights will correct for bias in the relationships between the variables.
There are six final weight variables in the dataset:
-
Finalweight – mixed mode for variables across both pathways
-
Finalweightweb – web only for variables across both pathways
-
Finalweight_CLS – mixed mode for variables in the Community pathway
-
Finalweightweb_CLS – web only for variables in the Community pathway
-
Finalweight_PS – mixed mode for variables in the Engagement pathway
-
Finalweightweb_PS – web only for variables in the Engagement pathway
-
International Territorial Level (ITL) is a geocode standard for referencing the subdivisions of the United Kingdom for statistical purposes, used by the Office for National Statistics (ONS). Since 1 January 2021, the ONS has encouraged the use of ITL as a replacement to Nomenclature of Territorial Units for Statistics (NUTS), with lookups between NUTS and ITL maintained and published until 2023. ↩
-
There were two exceptions to this rule: a minimum 250 in the City of London, and no minimum in the Isles of Scilly. ↩
-
Response rates were calculated via the standard ABOS method. An estimated 8% of ‘small user’ PAF addresses in England are assumed to be non-residential (derived from interviewer administered surveys). The average number of adults aged 16 and over per residential household, based on the Labour Force Survey, is 1.89. Thus, the response rate formula: Household RR = number of responding households / (number of issued addresses0.92); Individual RR = number of responses / (number of issued addresses0.92*1.89). The conversion rate is the simple ratio of the number of responses to the number of issued addresses. ↩
-
Interview lengths under 5 minutes for the community path and under 4 minutes for the engagement are removed, and they are capped at the 97th percentile. If interviews in the bottom 5% of complete times, they are flagged in the system for the research team to evaluate; if they are flagged for multiple other quality checks, then those interviews are removed. ↩
-
There was one exception to this rule. For the question Assets2: “For each of the following, please indicate whether there is at least one within a 15–20-minute walk from your home, further away but still in your local area, or there is not one in your local area at all”, option K: “Place of worship for my faith or religion, such as a church, mosque, temple” was treated differently. In the Paper questionnaire, if a respondent didn’t provide an answer where they should have, rather than being coded to a -5, they were instead coded into answer code 5: “Not applicable I do not have a religion/faith” (an answer code which was only available for this facility). ↩