Human-centred ways of working with AI in intelligence analysis
Published 26 July 2023

© Crown copyright 2023
This publication is licensed under the terms of the Open Government Licence v3.0 except where otherwise stated. To view this licence, visit nationalarchives.gov.uk/doc/open-government-licence/version/3 or write to the Information Policy Team, The National Archives, Kew, London TW9 4DU, or email: psi@nationalarchives.gov.uk.
Where we have identified any third party copyright information you will need to obtain permission from the copyright holders concerned.
This publication is available at https://www.gov.uk/government/publications/human-centred-ways-of-working-with-ai-in-intelligence-analysis/human-centred-ways-of-working-with-ai-in-intelligence-analysis
Foreword
This biscuit book is for anyone who is interested in our current thinking on human-centric intelligence analysis and Artificial Intelligence (AI). Building on the definition in Dstl’s first biscuit book, we’ll say that AI consists of theories, tools, technologies and techniques developed to allow computer systems to perform tasks normally requiring human or biological intelligence 1.

Human-centric
This means thinking about how systems are or should be designed around people. It’s about how to make technology work for people, rather than making people work in ways that put technology first.
Intelligence analysis
Lots of people argue over what this is. We’re going to say it’s trying to find out stuff about the world, in order to decide what to do next. So it’s not about being smart, but what you know (or think you know).
AI is proving to be incredibly important in intelligence analysis. Lieutenant General “Jack” Shanahan talked about “getting AI off the bench and out of the lab” at one of our conferences, AIFest. This means not just making technology and measuring its impact in a lab, in nice, clean conditions, but taking it out into the wild, where it’s messy and hard to know what’s going on - is this easy for operators, analysts, scientists and technologists?
No!
This biscuit book presents some problems we’ve come across when trying to take technology into the wild.
The people we spoke to wanted to know:
- Do we really need AI?
- How do I know whether this AI is any good?
- How can I measure whether this is any good?
- Do we always need costly and disruptive scientific experimentation to show it works?
- How do we prevent bias – in analysts, datasets or even our own organisation?
- How can we trust each other and our systems?
Intelligence analysts and their customers also worry about whether AI is really helping with what they call ‘Decision Advantage’ and ‘Situation Awareness’.
This means having the right information in enough time to make decisions that create an advantage over adversaries. As we’ll see, it can be hard to work out if any of this is happening.
Introduction
Biscuit books are designed for you to be able to pick up and dip into with a cup of tea and a biscuit. With this one, we suggest a really large biscuit that can be broken in half, which might make the biscuit and the book more digestible.
We present some of the ideas we’ve found useful in working with AI, and we’ve tried to explain them in a non-technical way. We hope our guidelines explain why some approaches to setting up and evaluating your AI might not always work and others might help.
In order to do this, we first introduce some concepts that we think are what you need to know about before reading the guidelines. Then we show you the guidelines.
We think you could dip into this bit with half your (really large) biscuit and a cup of tea.
At the end, there’s a section that goes into the weeds. In other words, it goes into a little bit more detail about some of the concepts, and since this is a small book, they’re quite small weeds (but quite big concepts).
This section mentions some of the theories behind our findings. You can go and find out more about them if you’re interested.
It’s also useful if your bosses ask you why on earth you’re doing some of the strange things we’ve suggested – you can point them to the research!
At this point, you could eat the second half of your biscuit. And have another cup of tea.

Intelligence analysis: needles, haystacks, puzzles and mysteries
The intelligence we’re going to be talking about (in intelligence analysis) is not about being smart, but what you know.
An interest in this sort of intelligence is nothing new. Throughout history, having good intelligence has been critical to the success of many endeavours; we need to find out stuff and think about it in order to make good decisions.
Good intelligence analysis is a bit like being able to read people’s minds and predict the future. We’re in a good position if we can understand why things are happening (insight) and predict them (or use foresight).
In order to draw conclusions, analysts look at different:
- data
- information
- knowledge or understanding (sometimes including existing intelligence)
Imagine a detective gathering evidence in order to identify a likely suspect. Some of the evidence gathering is physical evidence (fingerprints or DNA), but the detective also looks at patterns of behaviour, for instance. The detective then finds links between the clues to discover whodunnit. Of course, sometimes detectives get it wrong, because they’re human.
Some people describe the intelligence analysis process as being like a jigsaw puzzle, or looking for a needle in a haystack.
Not all intelligence problems are the same. For troops fighting, the problem might be: ‘where is the enemy going to attack me?’ We could answer this question by looking for objects (tanks), and events (radio transmissions). We find the needles in the haystacks, put together the jigsaw pieces and voila, we have our answer.
As intelligence problems get bigger though, the jigsaw puzzle analogy doesn’t work.
Analysts looking at big problems, such as, ‘what will a country’s foreign policy be in ten years time?’ don’t have a definitive answer. They can only make predictions.
Are we looking for a needle? Is it in a haystack?
At this level the problem is more of a mystery than a puzzle. There’s no picture on the box to look at, and no-one knows how many pieces are in the puzzle or where the pieces are. Oh, and they’re also mixed up with pieces from other jigsaws, AND you keep pricking your finger on needles left lying around (from the haystacks).
Puzzles are like questions which can be solved with the addition of new structured information to achieve well-defined answers (that we can check).
Mysteries are more like problems rooted in human behaviours and other very complex phenomena; an analyst cannot necessarily know the answer but might know what events or activities to look for and try to figure out how they relate 2.
The nature of the problem hasn’t changed in thousands of years, but its character has.
In previous years, there were certain ways of gathering information:
- telescopes
- interception of written messages
- human spies
Sometimes there wasn’t enough information to really understand what was going on.
Now we have:
- drones
- satellites
- signals intelligence
- open-source intelligence
- radars
- cameras
Just to name a few!
Our problem is now too much information, which is sometimes expressed as the problem of the 4 V’s.
Volume
There is a far greater volume of information.
Variety
Information arrives in a variety of forms.
Velocity
Information arrives at different velocities, some of it really fast.
Veracity
Because there’s loads of information, of different types, constantly bombarding the analyst, it’s very hard for them to work out the veracity of the individual bits of information, or the information as a whole.
And that problem just keeps getting bigger. (If you wanted to make it the problem of the 8V’s, you could also add variability, validity, vagueness and volatility.)
All this data and information should be a good thing, but it would require millions of analysts to get through everything available. Even then the human brain just couldn’t process that much stuff and come up with good answers and predictions.
That’s why intelligence analysts need AI to give them some help.

Data, information, knowledge, wisdom
So we’ve got lots of data. Or is it information?
UK defence often use a concept known as the Data-Information-Knowledge-Wisdom (DIKW) pyramid.
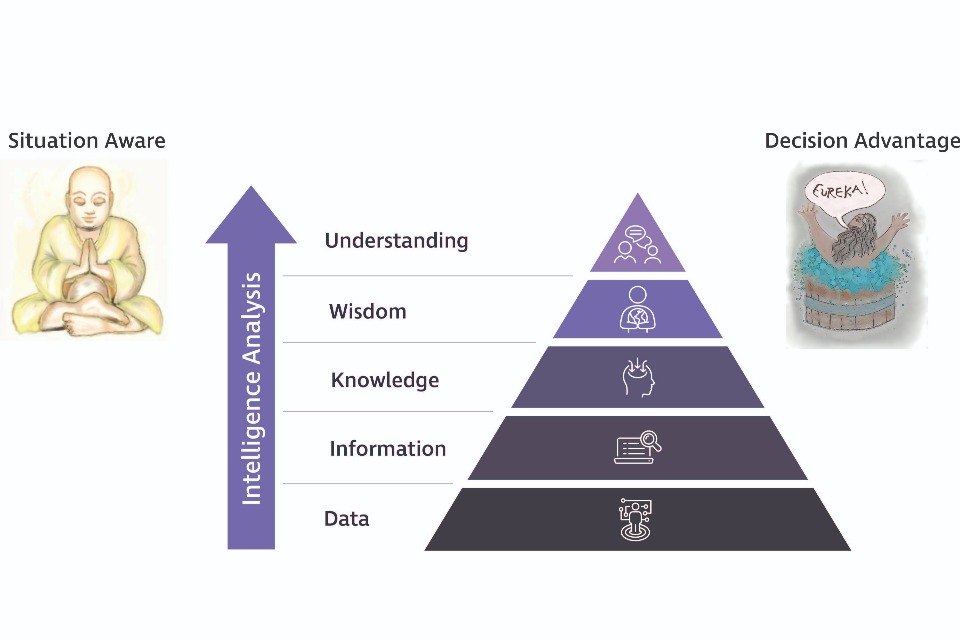
The idea (as shown in the graphic) is that data is the building block for ‘making’ information; that information creates knowledge, and then if you do the right things to the knowledge you might arrive at wisdom. Some people even say that if we transcend into the domain above wisdom, we achieve understanding. Each level must be enriched with meaning and context, or be processed in such a way that it becomes more meaningful.
The DIKW pyramid is a bit misleading. How exactly does data ascend to the giddy heights of knowledge? Does data ever exist without a context?
Most human-centred data is produced within a context, so how much more context does it need to become information?
Some people think processing data promotes it to the next level. They assume that doing things to data with algorithms creates our friends that we referred to in the foreword - ‘Decision Advantage’ and ‘Situation Awareness’.
Maybe this happens sometimes (and when it does, we love it) but we also need to think about:
- how precisely data contributes to the knowledge we need for decision-making
- how decisions are made in real environments (not just the lab)
- where the data has come from and why it exists
And it’s definitely not always straightforward to say how intelligence fits in to this. Or, how we know when it’s all working.
AI is also often part of a ‘data-driven’ approach to research. It sometimes contributes to evidence-based science or technology. In these approaches the results produced by ‘organising’ or processing data and information by means of algorithms are assumed to be knowledge or evidence bases. Sometimes this is true, but it often doesn’t work like that in complex situations.
Some research critiques these approaches, which can be referred to as reductionist, instrumentalist or operationalist approaches 3.
Reductionism means that a whole is no greater than the sum of its parts.
Instrumentalism means that we might not have to worry too much about the truth of things as long as we have something that we can use.
Operationalism in this context says that meaning exists only in things that can be observed and measured.
None of these approaches is wrong in themselves, but when misused and misunderstood, they can cause problems when applied in complex or complicated areas.
The following image shows how data is supposed to ‘ascend’ through information and knowledge to wisdom and understanding, enabling situation awareness and decision advantage.
Human Machine Teaming
Having thought a bit about intelligence analysis and knowledge, we’re now going to talk about Human Machine Teaming (HMT), which is just a way of understanding how to get people working well with technology (usually AI).
It’s complicated understanding the relationships between human and machine. We sometimes call these interdependencies. If we get the relationship right between the human and machine, then each is doing what they’re good at.
We often get asked to make intelligence analysts’ jobs easier by automating different bits of their work, using AI. This bit is fun. It’s not so fun when we’re asked to show if the AI helped the analyst.
Usually we do this by looking at factors (things) using measures – numbers that give information about what the AI and the analyst are doing. (There are other ways of assessing the technology on its own).
Factors you can measure
- Performance: Is the answer right? How fast are analysts working?
- Behavioural: Speech – what key words and phrases are analysts using? What proportion of their words has intelligence value?
- Physiological: Heart rate, change in heat and electricity passed through analysts’ skin
- Subjective: How demanding is the task? Do analysts trust the system? How easy or frustrating is it to use? (This sometimes includes an assessment called the NASA Task Load Index (TLX) 4.)
Collecting these measurements in a structured way, using experiments, is often called ‘using the scientific method’.
However when we did this, we found experimenting like this wasn’t as helpful as we’d hoped it would be; perhaps because intelligence work is not quite the same as other sorts of work that can get done using AI. As we said in the foreword, intelligence analysis is tricky.
We can make assessments about what might happen next (using AI). We can decide what to do next, and do it. But we rarely know what would have happened if we had done something else. We can set up models of the world and observe how people behave. But in the military there aren’t many people free to run controlled tests on (we definitely won’t mention how long it takes to get permission to do this).
So even if we can gather data, there might not be enough to have statistical significance if we try to do Proper Science. In fact, we found that sometimes measuring the impact of AI on intelligence analysis is a significant challenge.
Approaches to improving intelligence analysis
We decided to try and understand approaches to intelligence analysis itself a bit more, and how people have tried to improve it in the past. We thought we should do this before trying to work out how to improve it with AI (and then trying to evaluate the improvement).
We did the following:
- spoke to and observed intelligence experts as they worked with both old systems and new AIs
- talked to people working at all levels and analysts working in intelligence outside defence to see what they were doing differently
- read many books about intelligence analysis and decision-making
Knowledge, psychology, systems
We found there seemed to be 3 different approaches to describing what was going on in intelligence analysis. Because these were already a bit muddled, when we tried to incorporate AI support, it sometimes made things even more muddled.
We called these approaches:
- knowledge-based
- psychological
- systems approaches
Basically, these overlap, and people argue over which should be used; some of the arguing is about whether intelligence analysis is an art, a science or a craft.
Do we try to understand things like analysts’ skill and intuition (that’s the art or craft side) or use structured methods (using a more scientific approach)?
At the moment, it’s probably easier to design AI systems that support structured methods. It’s more difficult to use AI to support analyst intuition, but it’s something we’re trying to do. If we don’t keep these conflicts in mind, we find it hard to understand the complex problems that can crop up in intelligence analysis.
On the plus side, we found grouping these approaches together, and being aware of their limitations really helped.
Before we summarise our findings on knowledge, psychology and systems, we’re going to describe a few things we found out more about. They were hard to understand, but we really needed to try to understand them (a little) before drawing our conclusions together.
Theories of knowledge
We mentioned the DIKW pyramid in the introduction; we call this a theory of knowledge (the posh word is epistemology) as it provides a model of how knowledge can be derived (in this model, from data and information).
When we’re analysing news reports, social media feeds, financial markets, data from satellites or cameras, we’re building a picture of what’s happening in the world. Having a theory of knowledge means that we start out by methodically setting out how we know when or whether we can be certain about judgements that we are forming as we look at these reports, feeds, markets and data.
When we measure temperature, our theory of knowledge on temperature sets out how we know when the measurement is correct and incorrect. It might suggest that if we use a scientific method to collect data, alongside data we have collected previously, we can form predictions about future temperatures.
For this to work, we need to understand the methods used to collect our previous data so that we understand their compatibility. This means thinking about whether we are introducing errors or bias into the systems at a data level, by generating data in the wrong way, or more systemically, by misunderstanding what we’re seeing.
Analysts could be collecting Twitter data to understand how people in one county feel about an election, in order to make a prediction about voting patterns in another. But will the data from one area transpose to the area we are trying to make predictions about?
We need to formalise how we know when we’re doing it right.
Can our data and research methodologies really be aligned or synthesised? Where has the data come from? Why was it produced? Who are the stakeholders?
We must decide what might cause a failure in the process of knowing whether calculations, processes, observations and judgement are working (This is also very important for people looking at deception.)
Research methods
Research methods help us understand how data, information and knowledge are used through scientific and other approaches. There isn’t always time to use strictly scientific methods to evaluate and create ways of using AI. Science can help us to understand and make predictions about what we call ‘next generation’ or ‘generation after next’ technology, and help us work out what it might look like (because of timescales). For what defence calls ‘fight tonight’ though, we sometimes need to perform rougher, faster, less certain evaluations using different methods.
The graphic below visualises some common research methods. The right-hand side contains research approaches that are interpretive and descriptive; these are qualitative methods. The left-hand side contains approaches that can be numbers-based, countable or easily measurable; these are quantitative methods.
Some of these methods are better to use than others for evaluation of AI for intelligence analysis in real, fast-unfolding situations. For example, many qualitative methods are more appropriate for understanding some of the human-centred approaches to decision-making we will be describing. We’ve found it useful to consider both sides together in building a strong research design. The work of Katrin Niglas [5] is very helpful if you want to find out more.
The following image illustrates how you could work out how to think about your problem (is it hard science or more qualitative?) what you’re going to look for (will it be causal relations, correlations or interpretations?) and what you will actually do (the methodology)?

AI approaches
Something that helps us understand what people and systems do best is to think of AI as having two sorts of approaches.
Some approaches are human-centred and support how humans really think and behave. They can help analysts understand their own judgement or intuition. Others are what we call rationalistic which focus on processing huge amounts of data very fast. They can help us get information quickly (which would require a massive workforce to sift through if done by hand) - lots of technology will be a mixture of both.
Sometimes confusion creeps in about what AI and humans can do and what they should do.
Many researchers have wanted to correct human thinking and make it more rational or logical (this has been a topic of research for centuries); it’s happened in human-machine teaming. Clever people have spent time pointing out biases in analysts and also producing systems or technology in ways that make assumptions about how they think our minds should work.
This is really important, but doesn’t take into account that although we can do logic and understand what rationality is, as people we’re not designed to be perfectly logical and rational all the time. We all have different backgrounds, education and experiences. If we spend time learning a subject really well we carry around knowledge in a way that can sometimes be expressed in the form of intuition, or ‘practical wisdom’. This knowledge is not easily expressed in rational, logical ways.
There is also the fact that AI itself can suffer from bias that’s not easily unpicked.
Where AI replaces people
One of the reasons for automation was to replace costly, scarce or unavailable humans with machines. There are not enough people to process and exploit all the data and information we collect. However, as AI helps us, we discover more about the things that people can do that machines just can’t. AI research is an ongoing experiment on what it means to be human.
Quite often human abilities are not really understood or appreciated until we try to reproduce them with technology. This is especially true of human judgement, wisdom and intuition. We think these are sometimes overlooked in the revisited interest in AI. The currently popular classes of AI called ‘Machine Learning and Data Science’ often seem to lack human context (although earlier ‘symbolic’ AI research realised its importance). We hope these approaches will eventually align.
We also need to keep thinking about interdependence; the often changing relationship between people and systems, and understanding what they each do best.
Naturalistic Decision Making (NDM)
As we have said, some AI is not human-centred; it makes assumptions about how humans make decisions, and it doesn’t express its own decisions in the same way we do. Or it sounds human but is actually not doing what it seems to be doing. Analysts working alongside some AIs have reported feeling as though they’re baby-sitting a narrow-minded genius. AI designers can assume that AI is replacing our faulty minds with perfect logic, when in fact they sometimes fail to understand the complexity of human decision-making.
Naturalistic Decision Making (NDM) is one school of research (often ignored by technologists) that has suggested how the human mind really works when under pressure in realistic, non-laboratory conditions.
Factors that can define NDM:
- situations can be dynamic and fast-changing and so representing them is not simple
- causes of problems can be hard to break down which makes it difficult to decide what to do next
- those trying to define tasks in order to deal with a situation might be dealing with constantly shifting goals as new crises come in
- each decision is affected by previous decisions being made and others being made simultaneously
Recognition primed decision making
A branch of NDM is concerned with recognition-primed decision-making (RPDM).
RPDM is based on understanding how people such as fire-fighters, racing drivers or surgeons make quick assessments about what to do next in emergencies.
They’re not logically evaluating different courses of action, assigning weights and numbers to probabilities, like a computer might. Instead they are imagining what they might do and how this could turn out, given their recognition of a situation as being like something they’ve previously experienced.
Expertise is crucial for this. You have to recall the course of events that might have led up to a previously observed situation and to imagine what might happen if you do what you did last time. If you want to find out more about this, a good place to start is with Gary Klein, ‘Sources of Power’ 6.
This approach seems to capture much that AIs are unable to do, currently. Although much of AI involves pattern matching, it’s very hard to situate these capabilities within the contexts that humans can who are expert in domains such as racing, fire-fighting and surgery. We think that understanding how analysis works in these sorts of situation is crucial.
We need to ensure that AI for intelligence gathering and decision-making is human-centred and takes account of RPDM when needed.
Those were some of the tricky bits…now how have they helped us better understand the 3 approaches we mentioned that were at odds with each other?
So what about knowledge, psychology and systems?
As we said, we found 3 ways of looking at intelligence disciplines: knowledge, analyst experience (or psychology) and systems. We thought these should be examined together.
Knowledge
We found bad technology promotes the use of data to produce intelligence with no theory of knowledge or understanding of the data’s history or its journey. You might have an amazing team of people who spend weeks, months and years ‘cleaning’ your data, ready for use, but what if they don’t have a nuanced understanding of where it’s come from, and the cleaning has changed or even scrubbed away the meanings it will produce?
To offset this, think about what knowledge is produced, what are its inputs and what are the transformative processes. What social practice produces data?
For example, crime data is commonly referred to in the news. How is it produced? Is it through a police officer deciding what crimes to record on the beat, as opposed to giving people verbal warnings? How does the environment they’re walking through affect whether they ‘make’ a crime?
They may often (rightly) use their influence and local knowledge to prevent crime without producing data. We don’t know much about prevented crime, which means we can’t really use crime data to predict ‘naturally occurring’ crime or understand the real causes of crime - what are the research methods we can use to analyse this?
Good technology should also be as transparent as possible in allowing us to understand some of this.
Experience
This approach is offset by the psychological approach. Good psychology understands that an analyst must sometimes use their skills and wisdom in ways that might not always seem objective, in order to find and use their hard-earned insight.
Bad psychology hinders the analyst by replacing healthy scepticism about what they’re seeing with overwhelming self-doubt. If an analyst is dealing with a complex fast changing situation (if they’re doing naturalistic decision-making), it’s vital not to confuse their experience of the chaos of the real world with too much doubt in their own interpretation of what they see. In practice this is very hard to do, and managing this uncertainty will cause a lot of stress.
How does the analyst interact with their AI? Which systemic processes affect their experience of their work? How might their own tiredness, alertness, subjectivity or education affect the creation of intelligence? What measures or assurances can be put in place to manage this?
Systems
Both of the above approaches have been countered by attempts to systematise intelligence analysis. Good systemic approaches let analysts work in a way that supports their work-life balance, need for training, and let the organisation keep an overview. Bad structures prioritise processes, systems and rules over being human-centred.
What systems are being used? What lies behind them? What power, politics, personalities, and permissions are involved?
What we learned
The following principles are extracted from the work we did exploring the tensions between knowledge, psychology and systems (we found many more, but these seem the most relevant). They could be useful for designers, developers, regulators, users and assessors (these roles might often overlap, and they’re not always fixed).
The principles can be applied when you’re trying to develop or embed technology in your organisation - they won’t solve all your problems, but they give you a place to start your journey from. Some of them can also help you think about whether the AI is working well or not.
They helped us better understand from the human perspective what’s happening within analysis when AI is brought in. We also learned how we can know (quickly) whether very new or very experimental technology is improving our decision support and the experience of analysts.
The principles are:
1. Teach analysts to help themselves
Users of technology should feel as though they’re part of what’s going on. Generally, those using the systems should help to define the metrics or evaluation of the systems. There may be some capacity for objective assessment built into your systems, but consider how useful the answers are. Users should feel able to ask for professional advice but not feel forced in to it. They should be able to help themselves. (Especially to biscuits.)
2. Start your knowledge work
What are you trying to find out? How will the technology help you? What might distort the understanding that you’re looking for?
Thinking like this helps to build a practical theory of knowledge.
-
Start soon. If you’re designing a system from scratch, start asking these questions and then repeat them when you’re interviewing people to find out if or how the system’s working.
-
Define your stakeholders, and look for conflicts between them. This means you’re looking for influence (potentially from a distance) that might distort how your knowledge is produced.
-
Begin with those who the analysts respond to; the decision-makers. This is sometimes covered by legal, regulatory and commercial departments who may handle some of these analyses if you’re bringing in large AI systems from vendors, as risk management. Bring these analyses together.
-
Think about the following questions: what are the declared political views of any of your software providers? What might their undeclared views be? What else do they have stakes in? Technology is often political at some level and can be an expression of ideology.
-
Understand your stakeholders. This means knowing who should provide feedback on software. At the least you should include those commissioning the software, the users and the technology designers. What are your stakeholder’s measures of performance and success? Do they conflict in any way?
-
Note whether you’re working with a visionary or someone wanting a faster horse - those paying for software don’t always understand the process the software is replacing. If they instruct a coder to design software around their concept, what gets designed might not answer the real intelligence problem. Visionary and ‘faster horse’ are both relevant but be aware of the difference!
-
Consider validation and verification from the outset, even if you’re adding datasets in as you go. How will you know when it’s working?
-
Think about data sets. What are you looking at? Are you looking at soundwaves or groups of people? Cloud movements or market indexes? What sorts of knowledge are involved? What methods have been used to produce and transform the knowledge? Exploratory work should be done. Think about what models are being worked from and produced. If you have partial data then your results might be misleading.
-
Think about what incentivises data production. Is the data produced to meet targets (crime data, health data, education data often are)? If so, it’s probably not representative of real situations but of people’s perceptions of how they should be addressing those situations and the corresponding production of data. The data might even be the result of perverse incentives where the system is ‘gamed’.
-
Consider whether datasets can be synthesised in any way - or would this produce meaningless intelligence? Where is the data from? Why was it produced? Is it what it says it is?
-
Determine what might cause failure. How do you know whether calculations, processes, observations, analysis, judgement and intuition are working? Think about your analyst experience holistically and constructively. Might there be corrupted data, misinformation and environmental constraints? What about analyst education, state of mind, trusted relationships and the organisation they work within? Are you working with a diverse population of analysts? Diversity can build robustness and creativity into your processes, but it can fail if technology supports only one way of thinking.
-
Be mindful of the fact that if organisational culture is not well understood, it can swamp any attempt to introduce technology.
3. Talk to systems experts
It’s worth mapping out your technological systems. Intelligence analysis can rely on a lot of old systems that have new ones layered on top. Sometimes the relationship between systems is not clear to anyone.
Do the following:
- think about where your systems are transparent and which bits are hidden
- think about things such as, what names are used (are they misleading?), how the systems are visualised and whether it’s clear what they can and can’t do
- talk to everyone involved and get as many plans, blueprints, formal systems analyses and specifications from them as you can
4. Define the taskflow
As part of this systems analysis you can also conduct Task Analyses such as a Cognitive Task Analysis. This may have already been partially done before the software was brought in, but if it’s a very new capability there might be no ‘before’.
Cognitive Task Analyses should really try to understand what factors go into analyst judgement such as cues, expectations and critical decision points. Find out more about knowledge elicitation.
5. Understand research ethics
If you’re assessing how people use your system, what ethical constraints are there on carrying out this assessment? If organisations are working together, say a software firm, defence and academic advisers, you might have to carry out two or more lots of ethical assessment. Do you need to consult with any research ethics oversight teams in order to conduct formal research? Do this early on.
Beware of confusion in terminology too; words such as, ethics, governance, audit, assurance and best-practice are often used interchangeably. Sometimes this is about defining and controlling what people do, as well as the ability to track back and know how someone did their job. Other times, it’s more about freedom to do a job as well as possible and to know what to do as you go.
If interviewing people, consider whether they might dissociate from the effects of the technology they’re using. If the technology is too helpful they might get bored. This means they might not report on their own experience accurately.
On the other hand, someone with good self-awareness or accurate recall might find it difficult to answer the questions you’re asking. For example, sometimes emergency call handlers are upset by some of the calls they receive. If you plan to interview them about the technology they use to do this, think about what your research ethics panel(s) might ask.
6. NASA Task Load Index
The NASA Task Load Index (TLX) is a simple questionnaire which asks people to say how they feel about the ease or difficulty of their work. Those filling out the questionnaire make a series of choices describing the nature of a task, for example, if the task is more mentally demanding or physically demanding. It’s a quick and easy way of getting a rough benchmark on your system. You can use it before AI or any technology is introduced, after AI has been brought in and at various points thereafter to understand learning curves and analyst experience.
Think about how to:
- talk to those who will be using the TLX (explain what it’s for)
- reassure analysts that their performance is not under review (and be rigidly accountable for this) and the questionnaire is for the purposes of understanding what they do and how to make it easier for them
- obtain consent
There are a number of other online questionnaires that also look at:
- trust in systems
- demographics
- situation awareness
- system usability scale
- output quality
Look them up and work out which ones will support your efforts.
As you get a feel for what you’re doing, whether designing or assessing a human machine team layout, you can develop questions cooperatively around these points to ask everyone as you go along. We found this helped us see where the lack of balance is in working with new software or systems.
As you develop your questions and come to interview people (if you are interviewing) it’s also important to remember that you, as interviewer, can affect what answers are produced. We recommend training in interviewing and counselling skills, building trust and understanding organisational psychodynamics.
We also think about what is called Eudaimonia. We see this as helping people get the best out of their job and to feel that they’re doing it for the right reasons. Technology should support this.
7. Trust and transparency
We’ve mentioned questionnaires on trust and transparency in systems. Within intelligence analysis, trust in systems is a crucial component that determines how AI gets used, and its overall effect on the team. Transparency is also key; the more transparent systems are about what they’re doing and how, the faster analysts can make decisions about whether the system is providing them with the bits of the jigsaw they need.
Don’t forget that when an analyst is asking a system to help them understand the real world, they will often compare any answer given against other answers from other places. They’re not just finding out about the world, but also the system. If the system is not transparent about how it got its answer, the analyst will trust it less (and this slows everything down).
Untrusted systems worth millions of pounds can be found worldwide in dark cupboards, covered in dust; unloved, abandoned and alone. Do not contribute to creating these poor systems!

8. Experimentation in naturalistic settings
When we went about our own experimentation, we accepted that it wouldn’t be easy to carry out in a lab. There was a need to test things ‘in the wild’ with the user and the technology, which is sometimes called ‘field to learn’. The complexity of the operating environment can’t always be replicated in the lab. This is why we looked at supporting naturalistic decision-making.
Remember the part about research methods? There’s plenty of room to use the scientific method alongside other methodological approaches. We’re evolving our understanding of how to work across the range of methods in order to capture how to do good HMT. We describe this as ‘learning by doing’.
We try out approaches, get feedback from users and then try again. Getting AI off the bench, out of the lab and into the hands of real users with messy problems means using all the research methods available to us. For example, it’s OK to just get users to talk about how they think the system is working. Even if they’re not accurately assessing their own performance, their experience is relevant.
Through better understanding of some of these approaches we can really start to find out - not just whether analyst workload is reduced - but whether the introduction of new technology is really helping intelligence analysis.
To return to the first questions we asked about decision advantage and situation awareness, we think that while decision advantage has been seen to be supported by data and algorithms, it’s important to also think about a third factor. This is the naturalistic part of the decision-making in the wild that feeds decision advantage.
Another way to think about it is through timeliness, effectiveness and survivability. People often think that decision advantage is gained only through speed. Realistically AI can speed up decision cycles from days and weeks to minutes. But some of that is then going to be lost by having to unpick the answers and work out why it has come up with the answers it has. This is still contributing to effectiveness; by having better quality decision-making occurring even in real, complex and unpredictable situations.
Intelligence analysis has some very specific characteristics that are not always easily captured by traditional experimentation. The approaches in here have helped us to explore this incredible new technological world. We hope that as you nibble on your biscuit and sip your tea, you might feel more confident about working with AI in more uncertain situations.
In the weeds
This section provides a bit more detail for anyone interested in finding out more about some of the opposing perspectives we’ve mentioned. (You can also point to it if anyone asks you why you’re mentioning some of our wild ideas.)
The psychology of intelligence analysis
HMT means understanding how intelligence analysts work and what problems they might face that technology can help or hinder. Psychology has offered a number of approaches, and one is to examine bias in analysts.
Work on bias has included research into bounded rationality. Herbert Simon described humans as “organisms of limited computational ability” 7. Humans can’t gather or process all the information needed to make fully rational decisions - instead they satisfice or approximate - we’re also constrained by personal relations and organisational culture. It’s a good description of humans but it tends to cast being human as negative.
More research looked into expert decision-making. Experts’ predictions were compared to systems prediction when there was a known correct answer. In 1954 Paul Meehl showed that ‘experts’ got it wrong more often than the systems, according to the research, because of an inability to reason statistically.
Kahneman and Tversky conducted many experiments on what they called heuristics and biases. Again, these experiments were usually under laboratory conditions where there was a right answer. Kahneman wrote ‘Thinking Fast and Slow’, and suggested the idea of System 1 and System 2 thinking, which is explained in their article8.
Impact on intelligence analysis
The CIA’s Richards Heuer wrote some brilliant work on the topic of the psychology of intelligence analysis. However, it was the work he did on structured analytic techniques that influenced how a lot of intelligence analysis has been approached when it comes to automation. Heuer liked the System 1 and System 2 analogy:
“All biases, except the personal self-interest bias are the result of fast, unconscious, and intuitive thinking (System 1) – not the result of thoughtful reasoning (System 2). System 1 thinking is usually correct, but frequently influenced by various biases as well as insufficient knowledge and the inherent unknowability of the future. Structured Analytic Techniques are a type of System 2 thinking designed to help identify and overcome the analytic biases inherent of System 1 thinking” [9].
He suggested that not only do we have 2 ways of thinking (‘fast, unconscious and intuitive’, and ‘thoughtful reasoning’), but that these oppose one another, and ‘thoughtful reasoning’ is superior to intuition.
Heuer, and those he taught, believed that structured analytic techniques allow us to examine our own thinking in a more systemic and easy way. Later work fed in the idea of computer systems (especially AIs to offset the bad System 1 thinking). AI can easily and logically derive hidden information that is not laid out in clear statements. It provides the ‘reasoning’ of System 2.
This work suggested that analyst bias arose from their ways of thinking. In contrast to this, naturalistic decision-making research suggests that intuition is sometimes the only recourse in high-stakes, realistic environments, where the ‘right’ answer is unknowable. Analyst intuition is of high value, especially in out of the lab settings, and suggesting that thoughtful reasoning is superior creates a false opposition.
In practice we can balance these 2 approaches to create a broad psychology of intelligence analysis. It helps if we think about the degree to which information produced (perhaps some of it coloured by analyst cognitive biases) differs from objective views of reality (if these can be known).
As well as analyst bias, there is bias in AI systems themselves (which we consider here). In either case, we found that focusing too much on bias without any reference to ‘Theory of Knowledge’ meant losing too much that is useful.
Example: the off-course boat
Imagine your boss gives you clues to help you find and land on a secret beach. You’re decoding the clues as you sail. You reach a location which might be the right one, but no-one is there to let you know. Afterwards your boss (who loves heuristics and biases) says you were wrong, and suggests how to improve: get more sleep, wear better glasses, predict and account for the storm that blew you off course. You still do not know how to get to where you were meant to be. Often, in military cases, it turns out that no-one knows what the right choices were.

When we carry out assessments on how intelligence analysis works, cognitive bias research helps us roughly understand the types of errors we could make.
But we also need to know the degree of error between what any sort of bias is likely to produce and what the correct answers actually are. In real-world chaos, this is really hard to do, but we must try. The only way we can do this is to define what certainty, truth or reality are, (where this is possible), before talking about the degree to which we are steering off-course and why.
In other words, this is where theories of knowledge come in. A lot of the psychology of intelligence analysis has seen this as secondary to performing experiments on people that are somewhat lacking in what’s called ecological validity (they’re not very realistic). We love all forms of knowledge, but think that sometimes these experimental results are just not very useful to the intelligence production enterprise (they’re very useful elsewhere though).
Reality is messy. We often don’t know what our goals are in the next second, minute or hour. If we start talking about bias without a fix on how to get to the next objective, we’re probably mixing up our human-centred and rationalistic approaches.
We must try to understand analyst experience, in all its richness, whenever we are introducing HMT technology. The experience is what dictates any workload, especially if technology is not user-friendly. If we talk about the psychology of intelligence analysis we must focus on what analysts experience alongside knowledge and systems views. And we really shouldn’t talk about cognitive bias without also having a theory of knowledge.
Bias in AI systems
Many very intelligent people are now researching this, so we’re going to leave most of it to the experts.
AI is often not very transparent. The sorts of knowledge that AI systems contain is often similar to the knowledge of experts within a domain. We know it’s in there but it’s hard to get at. One recommendation (that many people are now following) is that for every cluster of machine learning specialists employed, there should be specialists who examine the social practices and the contexts that produce the datasets that have been used to train and then test the AI.
ImageNet is one of the underpinning training sets influencing computer vision research since its creation in 2009. One of its datasets spans 1000 object classes and contains 1,281,167 training images, 50,000 validation images and 100,000 test images. Deciding what images to use for a dataset that’s sort of meant to cover everything in the world meant finding a classificatory structure that…covered everything in the world.
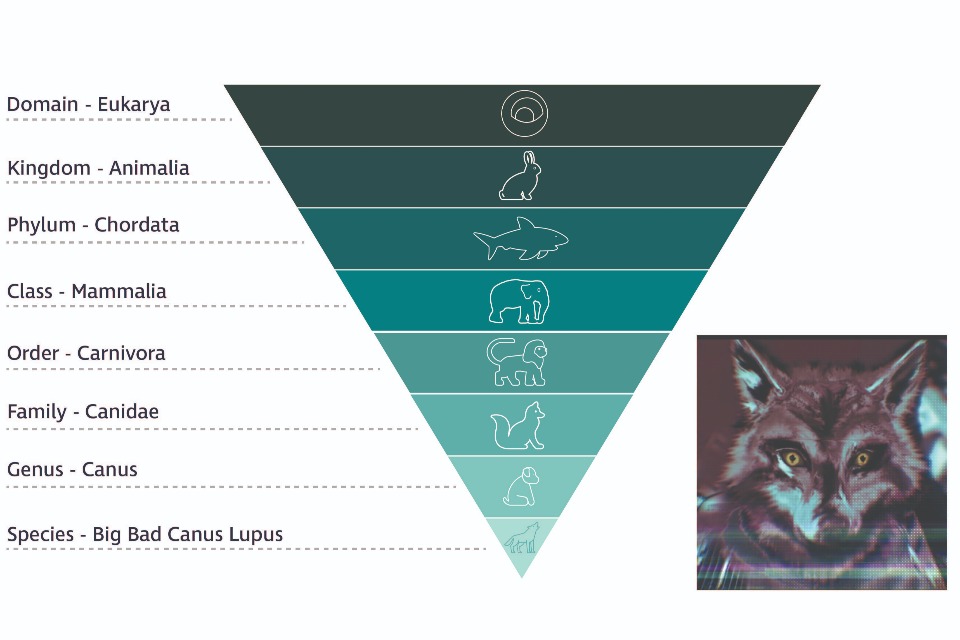
Such structures are referred to as semantic structures, ontologies or taxonomies. The taxonomy shown here is for a wolf, of the species canis lupus. The next level is its genus: canis, then its family is canidae, which sits in the order carnivore.
In the following image a taxonomy sub-divides classifications into smaller ‘classes’, in this example organisms in the animal kingdom are subdivided until we arrive at ’big bad wolves’.
ImageNet’s semantic structure was imported from WordNet, a database of word classifications first developed in 1985. However, WordNet itself rested on the Brown Corpus, which came from, “newspapers and a ramshackle collection of books including New Methods of Parapsychology, The Family Fallout Shelter and Who Rules the Marriage Bed?” 10. Most texts were published around 1961; the way people wrote about the world in 1960s America is very different to how we see things today.
Imagine being blindfolded and the only way you could ‘see things’ was to have your Kansas farmer great-grandfather look at the world and describe what he saw to you. Would he really understand the objects that we know of in the world today that he was describing? How would he describe mobile phones, drones and Fitbits? Might his descriptions seem biased?
This provides a rough idea about where bias might start to emerge in AI classification systems, which could be a vulnerability. Many people are concerned about transparency, or lack of, in AI. It’s possible that one day we’ll be able to unravel everything that goes into an identification that has been made by AI. This could include underpinning schemas that appear discriminatory, unethical or even illegal, since they come from such a long time ago. There could be reputational issues in store for governments or large corporations who use such methods.
Another cause for concern is how images in large datasets get labelled. There are businesses, organisations and governments in some parts of the world that pay workers tiny sums of money to identify and label images. Sometimes the only way for the bosses to check the labelling is correct is to ensure it falls in line with what the majority of the other workers are saying. This can create an echo chamber where truth is sacrificed for convenience.
“If you’re doing image recognition in 2019, it’s highly likely you’re using an image recognition system built by images tagged by people using Mechanical Turk in 2007 that sit on top of language classification systems built by graduate students prowling newspaper clippings in the 1960s. Simply put, every single piece of decision-making in a high-tech neural network initially rests on a human being manually putting something together and making a choice” [11].
The systems view of intelligence analysis
Attempts at improving intelligence analysis have been made through the overall concept of systematisation. For example, using structured analytic techniques, enhancing collection methods, to automating processes that don’t seem to need humans.
Systematisation has its problems. The ones we found that directly impacted human-centred HMT the most were to do with systems, loops and cycles. Consider the Observe Orient Decide Act (OODA) loop, and the Direct Collect Process Disseminate (DCPD) intelligence cycle. These approaches use systemisation and, like science-based approaches, suggest that if we’re all taught to do the same thing, following the same steps in the same set of circumstances, we can control and predict what might be happening.
Some of these approaches suggest that automated intelligence analysis can only be done this way. For example, by the movement of data through logical stages of collection, treatment and analysis, as though data is a raw material that is to be commoditised.
However, if we take the OODA loop, and then refer back to NDM, we might reflect that NDM would tend to suggest that in times of crisis, we observe, recognise, act, retroactively decide and orient – maybe more of a ORARDO loop?
Formalising the intelligence apparatus is a powerful way of helping to prevent intelligence failures. Nevertheless, having the right sort of data, processing it and adding new data, will not automatically create intelligence, or knowledge that feeds decision-making.
The intelligence cycle does not always work as it should. Sometimes we’re looking for evidence to show links and to attempt to prove, or disprove hypotheses. Sometimes we’re generally observing the world and creating and adding to a picture of what is going on. Most of the time we’re doing a messy mixture of both. How we treat data in these cases is crucial. We cover how or whether we should build hypotheses in these cycles here.
The philosophical view of intelligence analysis
The research in to systematisation in intelligence analysis led us to Isaac Ben Israel. He thought Philosophy of Science should be used in intelligence estimates, as both attempt to derive predictions from information. We think this is a very good idea. Philosophy of Science is a branch of philosophy that’s partially about epistemology, understanding the limits of what can be known, how and why. There’s a big overlap with intelligence analysis [12].
Ben Israel’s suggestion was that it’s wrong to look for evidence to confirm an idea, but we should try to disprove ideas instead. He was quite right to say this, at the time, but we think a broader approach is needed.
Ben Israel’s suggestion was based on Karl Popper’s work on falsifiability as a means of ‘doing science’. It tried to correct the problem of looking for evidence to confirm a hypothesis, and instead suggested that just as Popper had said science did, intelligence analysis should instead create hypotheses that are falsifiable.
The first issue is that, as we’ve said, intelligence analysis often needs a broader approach than just the scientific method in order to produce useful analysis.
The second issue is that Popper did not intend that falsification on its own should be used to ‘do science’. He did not say that we were only doing science if we falsified hypotheses. He intended falsifiability to show that we could know we were doing science if a hypothesis is potentially falsifiable.
In fact, falsification itself is a process that must end, and Popper suggested that this is where theories come to be accepted through agreement. Within this model the practice of science is not in itself scientific 13. However, people started thinking that the only good knowledge is scientific knowledge, gained through falsification.
This caused problems for intelligence analysis, which must process far broader ranges of phenomena than can be dealt with by science alone. When you see your enemy with a gun, there might not be time to falsify a hypothesis that the enemy is about to shoot. And definitely if they start raising the gun to their face (and it’s pointing at you), then it confirms your intuition that firing first or running (or both, if that’s how you roll) is the best option.
Falsifiability is not always necessary for intelligence analysis. This is one example of how challenging it is in real life, to get the AI out of the lab. The test bench is often very much about falsification, when it need not be.
Justified true belief
A useful concept that helps us bring knowledge into our analytic process is the concept of justified true belief (JTB). We think about how we acquire knowledge; this helps us understand the relationship between analyst experience and intelligence analysis. We’re observing the world and forming beliefs about it. If our beliefs are true, and they have been acquired in some way that means we’re right to have that belief, then we can say we have acquired knowledge.
Although there are criticisms of this approach, we found it enabled us to picture the intelligence analysis and decision-making environment and understand what factors might distort the analysis process. It also aligns with psychological research into situated cognition.
Situated cognition
We won’t go into a lot of detail here, but we really recommend reading about this:
“Complex systems will, inevitably, experience failures. The cause of these failures or mishaps may be labeled ‘operator error,’ but often they are actually caused by the confluence of technological, situational, individual, and organizational factors” [14].
Putting situated cognition, justified true belief and naturalistic decision-making together allowed us to better understand AI, data, knowledge and decision-making. Trying to explore these further helps understand where and when information might go missing (whether deliberate or a mishap).
We can also better understand the sorts of uncertainty that creep into our systems and how to act despite these constraints.
Practical wisdom
While doing our research we found out lots about ‘practical wisdom’.
The research that looks at this provides far richer, pragmatic and productive underpinning theories of knowledge for defence and security than just DIKW.
So just to finish off, we’re adding a few pointers here from researchers and experts who helped us work out useful approaches that we think feed into ‘practical wisdom’.
Makarius
Makarius has explored decision support, learning, knowledge dissemination, teams, trust, and socialisation 15. We found it helpful to think about HMT in terms of knowledge creation, professional and organisational practice, analyst experience and capability, including intuition, judgement and experience rather than just analyst burden or technology capability. The following table, taken from their paper, explains some of the questions to consider in bringing AI into organisations.
| Cognitive Issues | Relational Issues | Structural Issues |
|---|---|---|
| Strategic Decision Making | Teamwork | Job Design |
| How do decision makers trust the outputs from AI systems? What controls in decision making processes are needed when an AI system encounters an abnormality that requires human intervention? | What is the ideal team size and configuration of AI systems/robots and human team members? What are the team dynamics of working side by side with AI systems or robots? | What is the level of AI and employee interdependence? How will employee tasks change with AI systems? |
| Organisational Learning | Trust and Identification | Training and Development |
| How does transformational learning occur with AI systems? How does deep learning drive the organisational learning architecture on AI systems? | How can team identity be fostered between AI and employees working in a group? How can employees build trust with an AI system/robot? | How can we reskill workers to work successfully with AI systems? What type of technological and relational training is needed for non-technical employees working with AI systems? |
| Knowledge Sharing | Coordination | Socialisation |
| How can knowledge be managed and disseminated between AI systems and employees? How can tacit knowledge be learned by AI systems? | Will sequential, reciprocal or pooled coordination be most effective for AI systems and employees? How can relational coordination be developed? | How can organisational factors influence adaptation to AI systems and collaborative robots? How do anticipatory socialisation factors change when AI and robots are deeply engrained in company culture? |
Galbraith
A related way of looking at the big picture was from the organisational perspective provided by Galbraith. As change happens with AI being brought in, it can be helpful to re-examine each one of these areas; often in tension with each other [16].
The following image shows Galbraith’s model of organisational dimensions.

Cummings
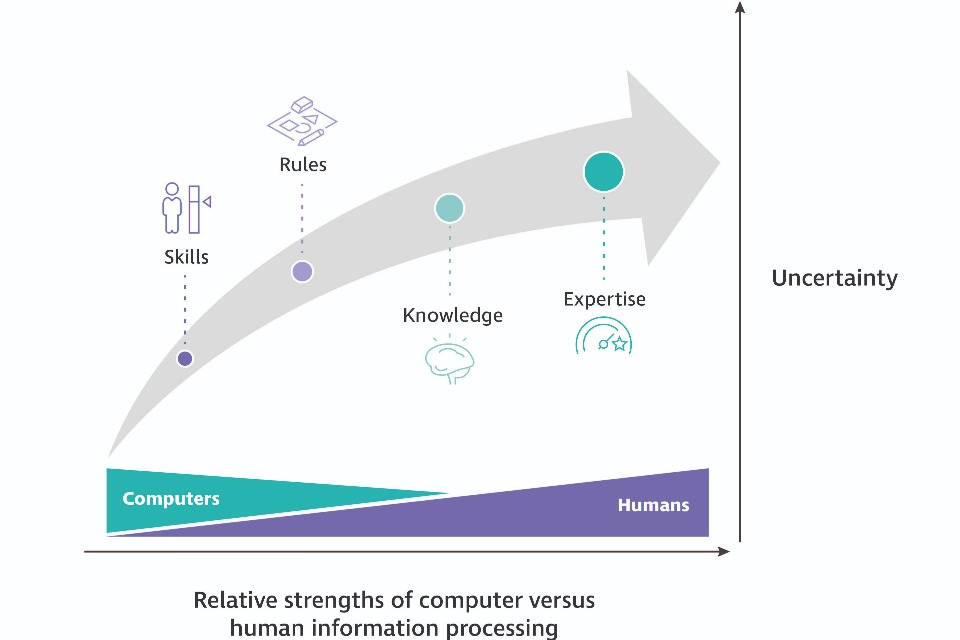
Cummings, a fighter pilot, has written about NDM and automation using skills, rules, knowledge and expertise 17. Skills-based reasoning comes first (for example, learning how to keep an aircraft balanced by using the turn and slip indicator alongside other controls and indicators). Spending time practicing these sorts of skills makes them automatic. Then there is cognitive reasoning for rules-based procedures.
“If something happens, do this.”
Knowledge-based reasoning deals with uncertain situations. In emergency situations, such as those Klein studied, experience allows us to make fast mental simulations, make predictions and then act. We can say that automation means having to assess a situation, understand what might happen, and to use skills-based reasoning first.
Over time, as a system learns more and more situations, this might lead to expertise, but this may never be on a par with human expertise.
Cynefin
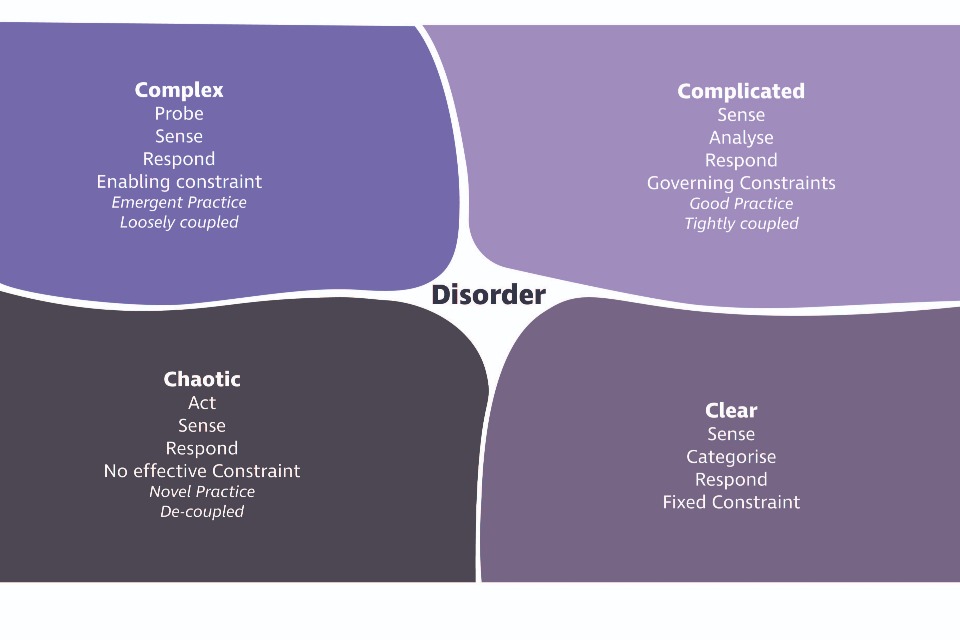
Finally, the Cynefin framework 18 can help to work out if you have a chaotic, ‘complicated’ or a ‘complex’ problem on your hands. (It’s almost inevitable if you’ve actually read this far, you won’t be worried about a ‘clear’ problem.)
The following image shows Snowden’s Cynefin model showing the difference between complex, complicated, chaotic and clear problems.
This concludes our journey into the weeds. We didn’t go too far and hope there’s just enough here to explore further if you want. If not, just enjoy your biscuit!
References
[1] The Dstl Biscuit Book Artificial Intelligence, Data Science and (mostly) Machine Learning. Ist edition revised v1.2 Published 2019 GOV.UK
[2] Treverton, G. F. (2007). Risks and riddles. Smithsonian, 38(3)
[3] Frické, M. (2019). Knowledge Pyramid - The DIKW Hierarchy . Encyclopedia of Knowledge Organization https://doi.org/10.5771/0943-7444-2019-1
[4] Sandra G. Hart, Lowell E. Staveland. (1988) Development of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research. Advances in Psychology. 52(pages 139-183) https://doi.org/10.1016/S0166-4115(08)62386-9
[5] Niglas, K. (2001). Paradigms and methodology in educational research. European conference on educational research, Lille
[6] Klein, G. (1998). Sources of Power: How people make decisions. MIT Press, ISBN https://doi.org/10.7551/mitpress/11307.001.0001
[7] Simon, H. A. (1955). A behavioral model of rational choice. Quarterly Journal of Economics, 69(1). https://doi.org/10.2307/1884852
[8] Kahneman, D. (2011). Thinking fast, thinking slow. Interpretation, Tavistock, London.https://doi.org/10.1007/s00362-013-0533-y
[9] Heuer, R. J. (1999). Psychology of Intelligence Analysis
[10] Crawford, K. (2021). The Atlas of AI. In The Atlas of AI. Yale University Press. https://doi.org/10.2307/j.ctv1ghv45t
[11] Boykis, V. (2019). Neural Nets are just people all the way down, Normcore Tech newsletter
[12] Ben-Israel, I. (2001). Philosophy and Methodology of Military Intelligence: Correspondence with Paul Feyerabend. In Philosophy and Methodology of Military intelligence-Correspondence with Paul Feyerabend, 28(4)
[13] Popper, K. (1935). The logic of scientific discovery. In The Logic of Scientific Discovery. https://doi.org/10.4324/9780203994627
[14] Shattuck, Nita & Shobe, Katharine & Shattuck, Lawrence. (2023). Extending the Dynamic Model of Situated Cognition to Submarine Command and Control
[15] Makarius, E., Mukherjee, D., Fox, J. D., & Fox, A. (2020). Rising With the Machines: A Sociotechnical Framework for Bringing Artificial Intelligence Into the Organization. Journal of Business Research, 120. https://doi.org/10.1016/j.jbusres.2020.07.045
[16] Galbraith, J. R. (2009). The Star Model. The STAR Model, 07/04/2017
[17] Cummings, M. M. (2014). Man versus machine or man + machine? In IEEE Intelligent Systems, 29(5). https://doi.org/10.1109/MIS.2014.87
[18] Snowden, D. (2002). Complex acts of knowing: Paradox and descriptive self-awareness. Journal of Knowledge Management, 6(2)https://doi.org/10.1108/13673270210424639